外接显卡驱动解锁:让你的Mac瞬间变身AI计算工作站
还记得那个深夜,老李坐在书桌前,盯着屏幕上那个缓慢运行的AI大模型,眉头锁得紧紧的。作为一名独立开发者,他一直有个梦想:用自己手头那台轻便的MacBookPro处理复杂的深度学习任务。但现实总是残酷的,由于硬件限制,很多算力密集型的工作只能望洋兴叹,直到最近,一个改变游戏规则的消息传到了他的耳朵里。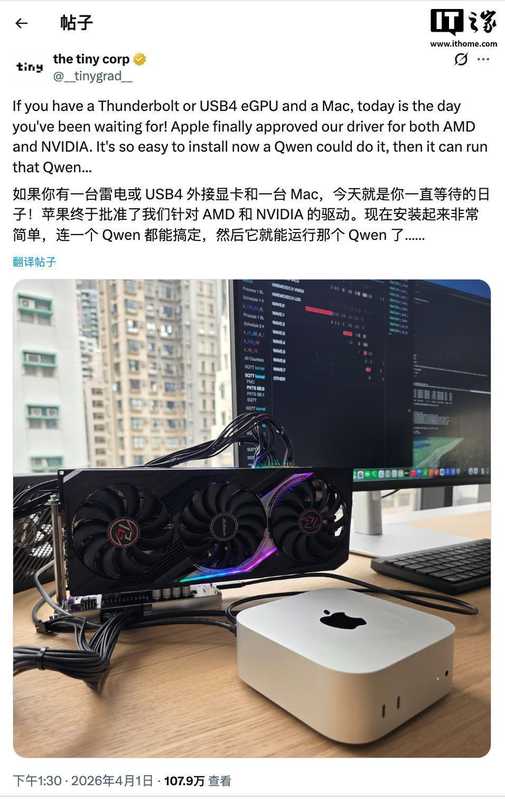
原来,苹果对AppleSilicon平台的外置显卡支持终于有了实质性的突破。曾经,想要在Mac上运行高性能AI模型,往往需要复杂的系统设置,甚至要冒着安全风险关闭系统完整性保护。而现在,TinyCorp带来的这套驱动方案,让一切变得简单起来。老李尝试着将那台搭载了强力GPU的设备连接到Mac上,安装过程顺利得让他有些不敢相信。曾经需要反复调试的繁琐步骤,现在只需简单的几步操作,系统就能识别并调用外置显卡进行运算。
看着那条原本缓慢的进度条飞速前进,老李感触颇深。这不仅仅是一个驱动的更新,更像是一把钥匙,打开了普通开发者通往高性能计算的大门。他意识到,这背后是TinyCorp团队对于AI计算生态的执着追求。他们不仅解决了驱动兼容性的难题,更重要的是,他们将原本高高在上的AI训练门槛,通过这种方式拉低到了普通用户的桌面。
这次成功的实践,给像老李这样的创作者们带来了巨大的信心。他开始思考如何利用手头的设备,去尝试运行那些之前想都不敢想的大模型。这种从“无法实现”到“触手可及”的转变,正是技术进步最迷人的地方。它告诉我们,只要有合适的方法,硬件的藩篱并非不可逾越。
驱动革新的深层逻辑
这套驱动方案的本质,在于它绕过了传统的图形渲染路径,直接针对AI大模型的计算特性进行了深度优化。传统的GPU驱动往往侧重于游戏图形渲染或专业视频编辑,而TinyCorp开发的这一路径,专注于Tensor计算效率。这意味着,当你在Mac上运行大模型推理时,数据流不再受限于系统内部的内存带宽瓶颈,而是通过外置显卡直接实现高速吞吐,极大地缩短了模型响应时间。
赋能开发者的实操建议
对于想要尝试这一方案的开发者,建议从轻量级模型入手进行测试。首先确保你的Mac运行在最新的系统版本上,并仔细阅读相关驱动的兼容性说明。在硬件连接方面,选择高质量的雷电接口线缆至关重要,这能保证数据传输的稳定性。不要急于追求极致的性能输出,先建立一套稳定的工作流,再根据实际的算力需求,逐步调整模型参数和batchsize,这样才能在保证系统稳定的前提下,最大限度地榨干外置GPU的性能潜力。
未来算力平民化的趋势
我们可以预见,随着这种第三方驱动方案的完善,AI开发的门槛将进一步降低。未来,或许我们不再需要昂贵的服务器集群,只需一台便携的Mac连接外置算力单元,就能完成大部分的科研与创作任务。这种“分布式计算”的理念,正在重塑个人电脑的使用场景,让每个人都能成为AI时代的参与者,而不仅仅是使用者。